@inproceedings{Liu_2025_CVPR,author={Liu, Shanglin and Lv, Jianming and Kang, Jingdan and Zhang, Huaidong and Liang, Zequan and He, Shengfeng},title={MODfinity: Unsupervised Domain Adaptation with Multimodal Information Flow Intertwining},booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)},month=jun,year={2025},pages={5092-5101},}
FS-Diff: Semantic guidance and clarity-aware simultaneous multimodal image fusion and super-resolution
Yuchan Jie, Yushen Xu, Xiaosong Li, and 3 more authors
@article{li2025hyperimts,title={HyperIMTS: Hypergraph Neural Network for Irregular Multivariate Time Series Forecasting},author={Li, Boyuan and Luo, Yicheng and Liu, Zhen and Zheng, Junhao and Lv, Jianming and Ma, Qianli},journal={Forty-Second International Conference on Machine Learning (ICML)},month=jul,year={2025},}
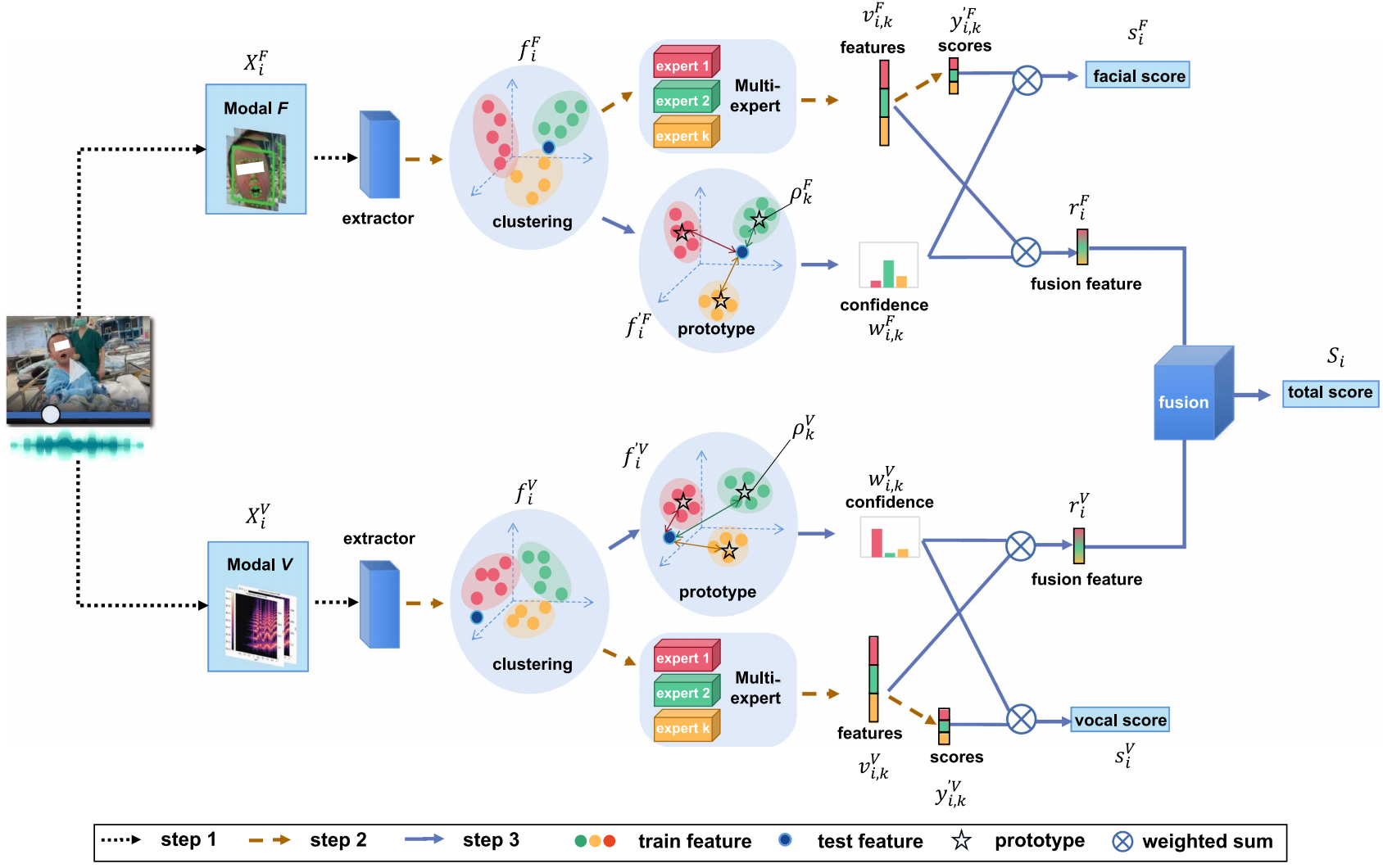
A multi-modal multi-expert framework for pain assessment in postoperative children
Zequan Liang, Hao Luo, Xi Chen, and 5 more authors
IEEE Transactions on Affective Computing, Jul 2025
@article{liang2025multi,title={A multi-modal multi-expert framework for pain assessment in postoperative children},author={Liang, Zequan and Luo, Hao and Chen, Xi and Zhong, Zhipeng and Fan, Cheng and Song, Xingrong and Li, Bilian and Lv, Jianming},journal={IEEE Transactions on Affective Computing},year={2025},publisher={IEEE},}
EdgeNeRF: Edge-Guided Regularization for Neural Radiance Fields from Sparse Views
Weiqi Yu, Yiyang Yao, Lin He, and 1 more author
The Eighth Chinese Conference on Pattern Recognition and Computer Vision, Oct 2025
@article{yu2026edgenerf,title={EdgeNeRF: Edge-Guided Regularization for Neural Radiance Fields from Sparse Views},author={Yu, Weiqi and Yao, Yiyang and He, Lin and Lv, Jianming},journal={The Eighth Chinese Conference on Pattern Recognition and Computer Vision},year={2025},month=oct,}
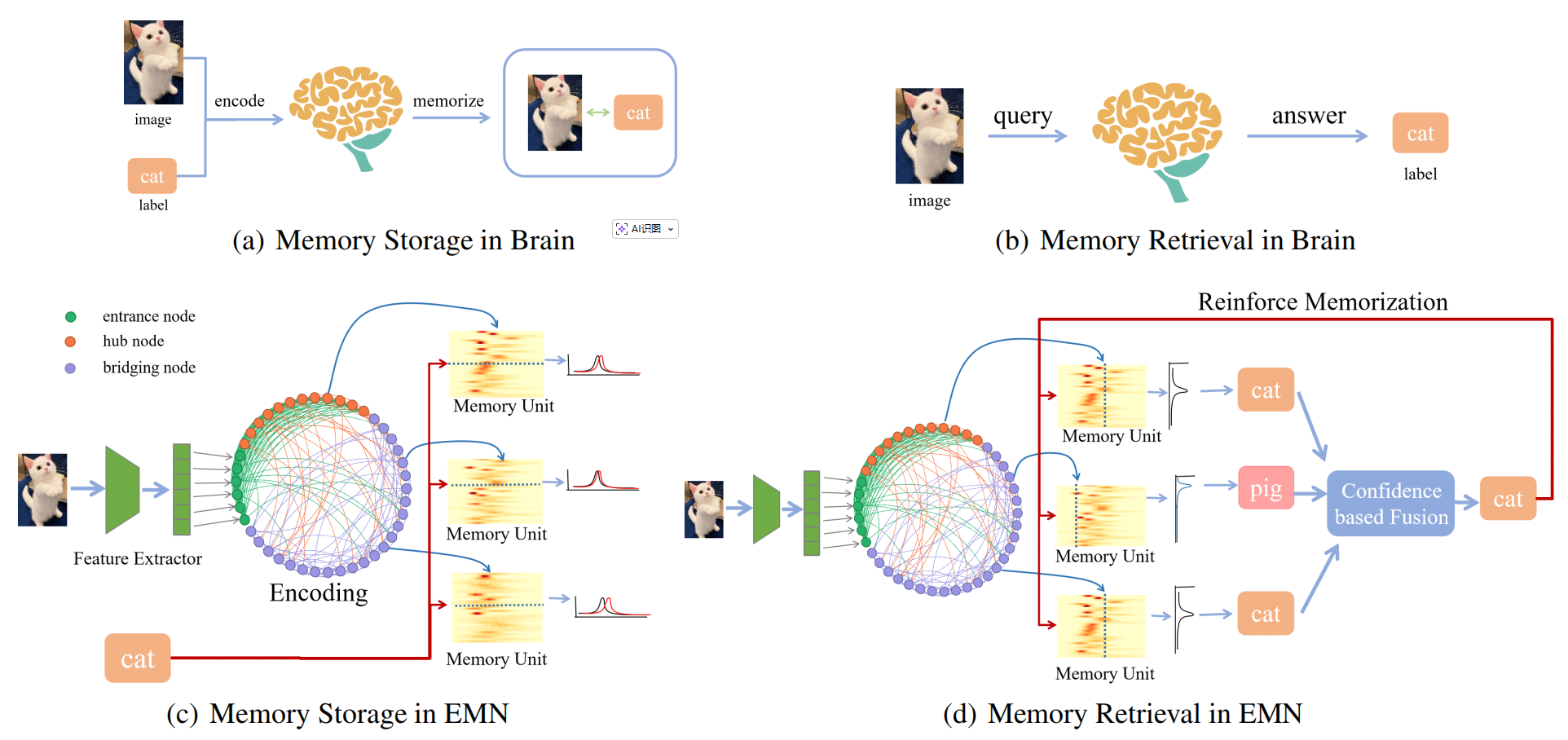
@article{lv2024emn,title={EMN: Brain-inspired Elastic Memory Network for Quick Domain Adaptive Feature Mapping},author={Lv, Jianming and Wang, Chengjun and Liang, Depin and Ma, Qianli and Chen, Wei and Cheng, Xueqi},journal={arXiv preprint arXiv:2402.14598},year={2024},}
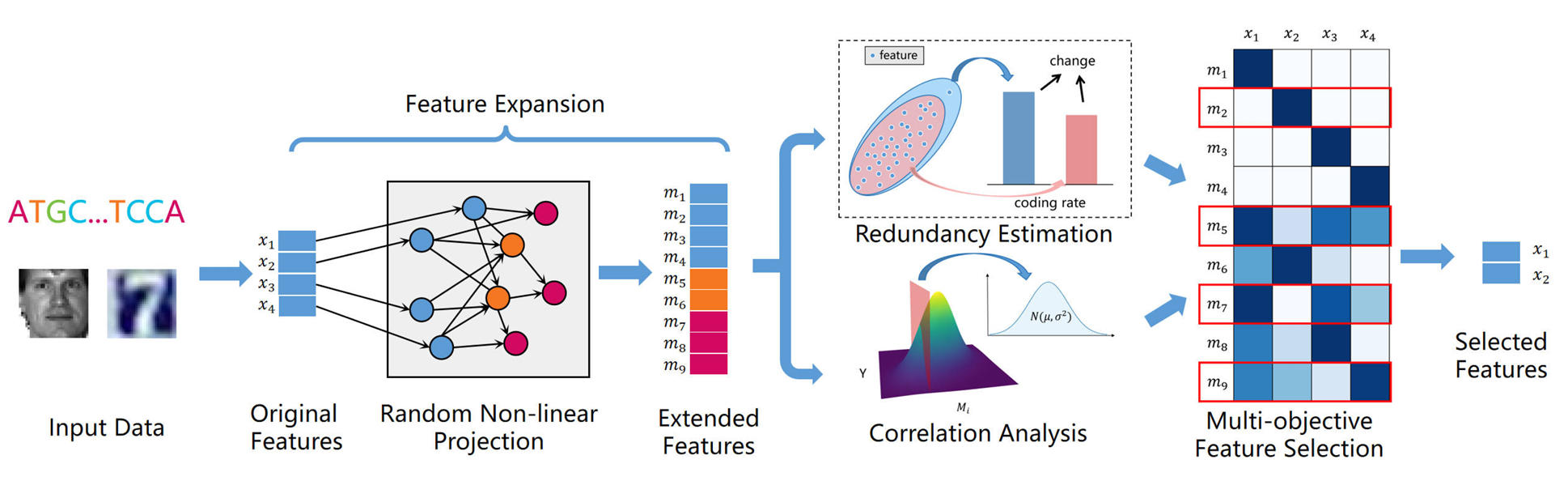
EasyFS: an Efficient Model-free Feature Selection Framework via Elastic Transformation of Features
Jianming Lv, Sijun Xia, Depin Liang, and 1 more author
@article{lv2024easyfs,title={EasyFS: an Efficient Model-free Feature Selection Framework via Elastic Transformation of Features},author={Lv, Jianming and Xia, Sijun and Liang, Depin and Chen, Wei},journal={arXiv preprint arXiv:2402.05954},year={2024},}
2023
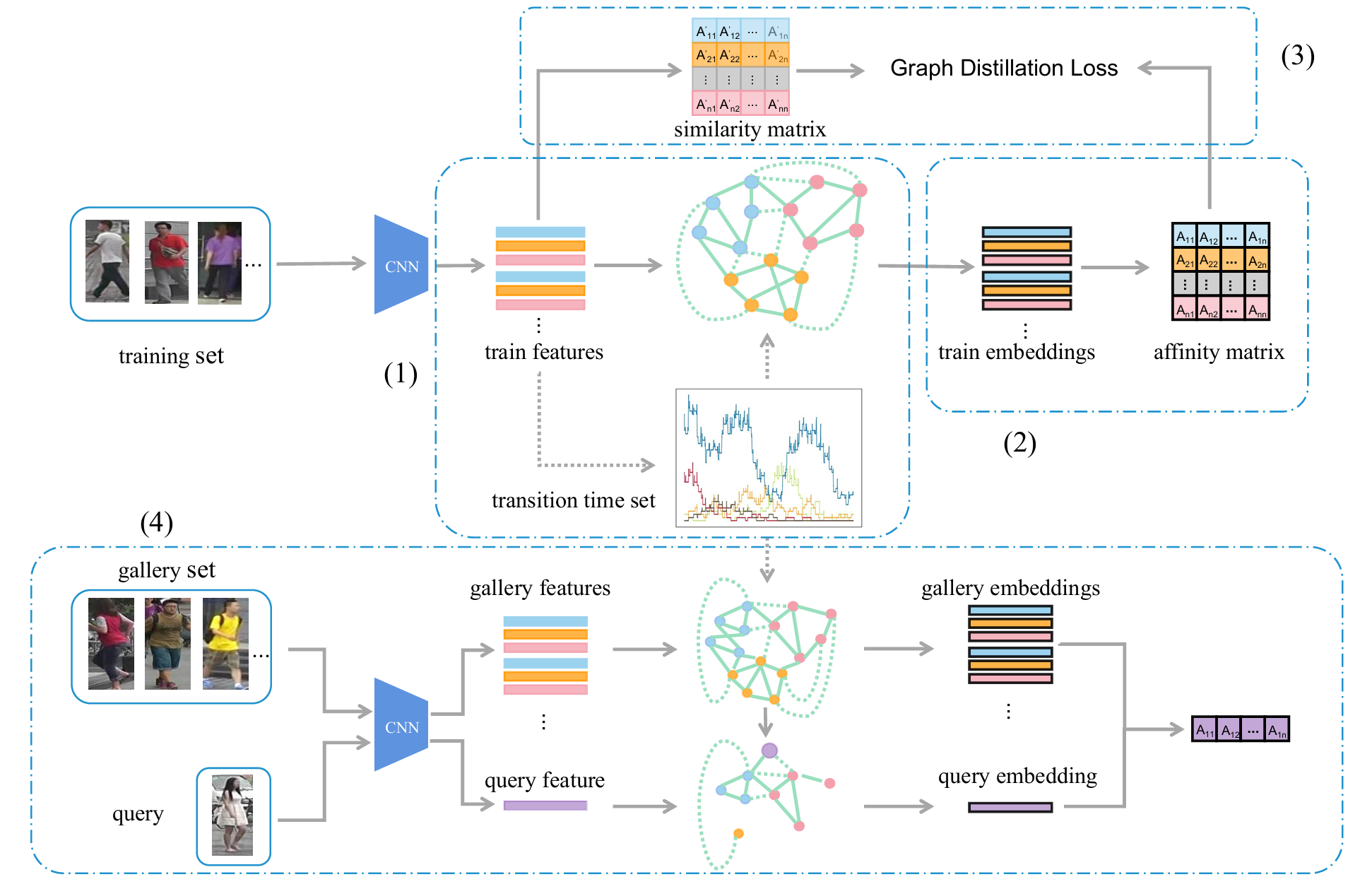
Graph based Spatial-temporal Fusion for Multi-modal Person Re-identification
Yaobin Zhang, Jianming Lv, Chen Liu, and 1 more author
In Proceedings of the 31st ACM International Conference on Multimedia, Oct 2023
@inproceedings{zhang2023graph,title={Graph based Spatial-temporal Fusion for Multi-modal Person Re-identification},author={Zhang, Yaobin and Lv, Jianming and Liu, Chen and Cai, Hongmin},booktitle={Proceedings of the 31st ACM International Conference on Multimedia},pages={3736--3744},year={2023},month=oct,}
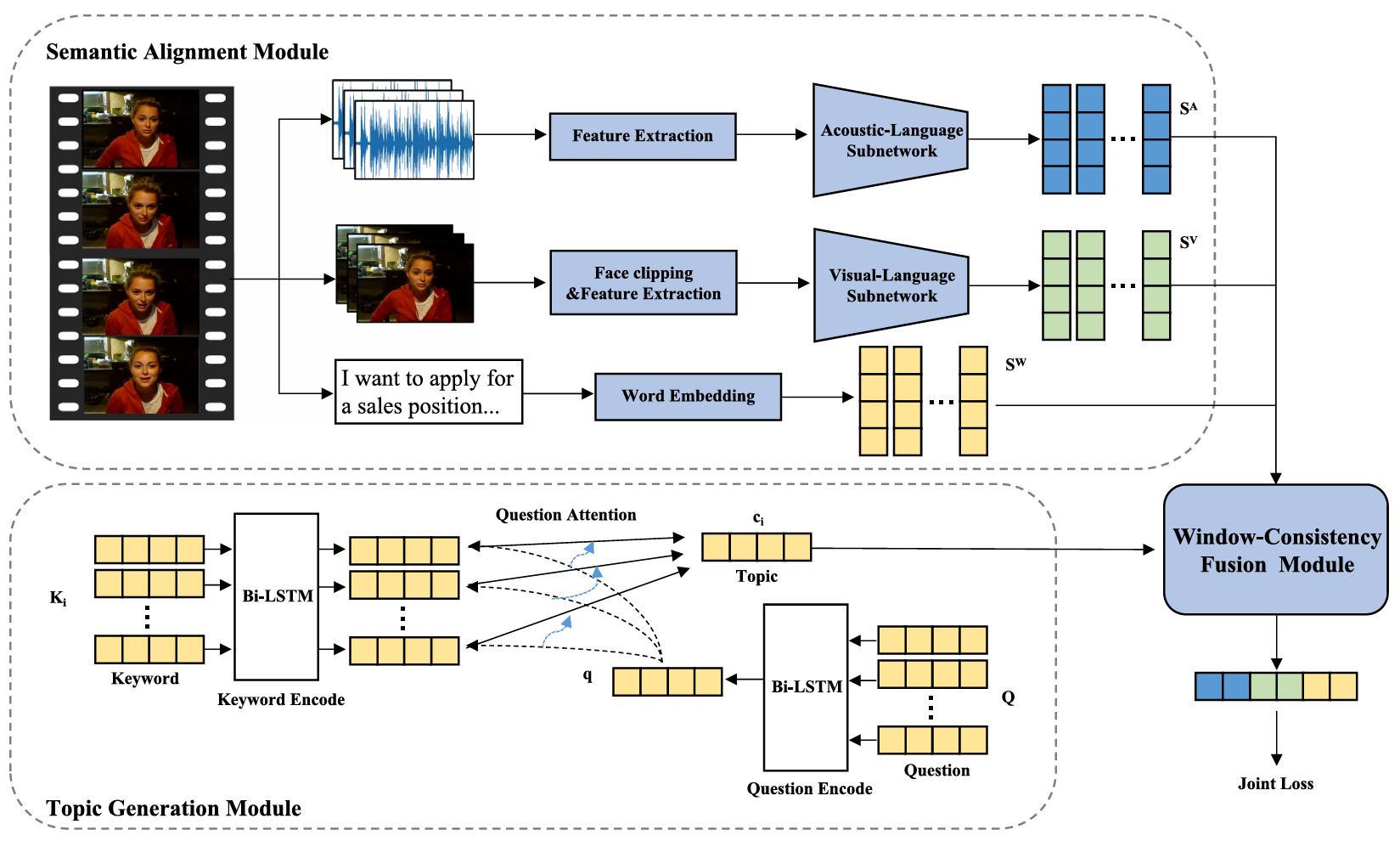
Automated Scoring of Asynchronous Interview Videos Based on Multi-Modal Window-Consistency Fusion
Jianming Lv, Chujie Chen, and Zequan Liang
IEEE Transactions on Affective Computing, Oct 2023
@article{lv2023automated,title={Automated Scoring of Asynchronous Interview Videos Based on Multi-Modal Window-Consistency Fusion},author={Lv, Jianming and Chen, Chujie and Liang, Zequan},journal={IEEE Transactions on Affective Computing},volume={15},number={3},pages={799--814},year={2023},publisher={IEEE},}
@inproceedings{Differentiated2021,author={Lv, Jianming and Liu, Kaijie and He, Shengfeng},title={Differentiated Learning for Multi-Modal Domain Adaptation},year={2021},isbn={9781450386517},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3474085.3475660},doi={10.1145/3474085.3475660},booktitle={Proceedings of the 29th ACM International Conference on Multimedia},pages={1322–1330},numpages={9},keywords={multi-modal analysis, domain adaptation, differentiated learning},series={MM '21},}
@article{chen2021adversarial,title={Adversarial caching training: Unsupervised inductive network representation learning on large-scale graphs},author={Chen, Junyang and Gong, Zhiguo and Wang, Wei and Wang, Cong and Xu, Zhenghua and Lv, Jianming and Li, Xueliang and Wu, Kaishun and Liu, Weiwen},journal={IEEE Transactions on Neural Networks and Learning Systems},volume={33},number={12},pages={7079--7090},year={2021},publisher={IEEE},}